

Copyright’s Next Chapter: When AI Meets Artistic Rights
Do we need new rules?

At a Glance: Last month, judges ruled on copyright cases related to Anthropic and Meta’s AI models. Courts found training to be fair use, but only when the content was legally acquired. AI companies are taking steps to address concerns while additional cases work their way through the courts and lawmakers consider regulations. Successful businesses must develop revenue models that benefit both consumers and artists.
The First Copyright
In 1486 the Venetian Senate granted author Marco Antonio Sabellico a “Venetian Privilege”, a legal monopoly over the printing of his history of Venice titled Decades rerum Venetarum. This was the first known instance of copyright, which protected him against unauthorized copies of his work by the newly invented printing press. Centuries later, copyright faces new tests with the rise of AI.

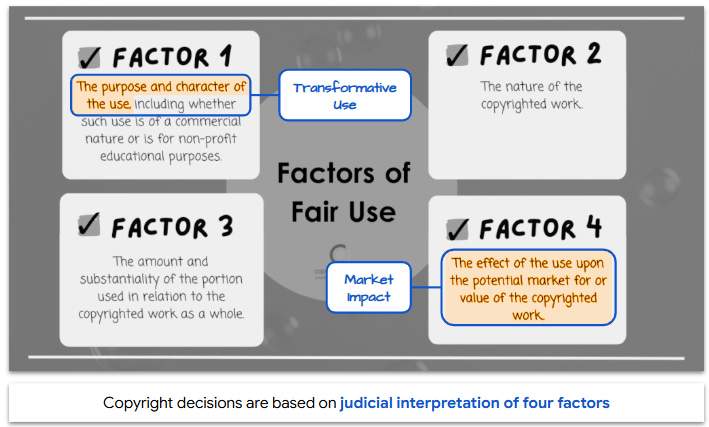
Copyright cases rely on four factors, the two most important for AI being transformation and market impact.
Transformation and Fair Use
Here’s how transformation works:
Imagine you memorize a Harry Potter book and then write an exact replica. That violates copyright (“copy” + “right”) law, which protects an author against unauthorized reproductions of their work.
Now imagine you memorize the Harry Potter, Percy Jackson and Hunger Games books and write a new book that combines ideas from all three. This is called transformational use “creating a new expression, meaning, or purpose” and is encouraged under copyright law.
AI companies argue that their models are transformational because the generative process creates new output instead of regurgitating works they were trained on.*
Assessing Market Impact
Market impact is simple to understand but difficult to determine: how does the new work affect the original’s profitability? This is a hotly debated point: Creators argue that AI-generated material competes with source works, while companies contend that demand for originals can even be enhanced when referenced in a model’s output.
Judges have initially sided with AI companies with two caveats: In Kadrey vs. Meta, Judge Vince Chhabria acknowledged Kadrey’s complaint about their their work being used for training but ruled for Meta because they couldn’t demonstrate market impact. In Authors Guild vs, Anthropic, Judge William Alsup ruled in favor of Anthropic on legally acquired works but against it for training on a set of 7 million pirated books.
These two cases suggest a precedent: training is fair use but companies are liable for the methods used to acquire content.
Challenges and Progress
AI companies are walking a tightrope when it comes to copyright. On one hand, they are competing in an intense battle to build the best model and need robust data to do so. On the other hand, using data incorrectly poses legal risks while court precedents are still emerging.
For companies seeking to pay individual authors, the technical challenge is daunting: models blend billions of datapoints, making it virtually impossible to trace outputs back to a specific source. Even if they could, most individual payments would be tiny; given the sheer scale of data, a single work is like a drop in an ocean of content.
AI companies are taking steps to address these challenges by signing licensing deals with major publishers (OpenAI + NewsCorp & Khan Academy, Google + Reddit, Perplexity + Reuters). They are also increasingly relying on owned data sources like Google’s YouTube, Meta’s Instagram, and X’s Twitter, while working with providers like ScaleAI to create new inputs they exclusively own.
What to Watch For
AI copyright issues are complex and rapidly evolving. Here are three things to look out for:
First: Legal Precedents
What happens in the courts? There are over forty more cases in process, many with high-profile plaintiffs like the New York Times, Reuters and Getty Images. If courts agree on fair use of authorized content companies will likely settle and develop compensation systems. If not (or even if so), there is a good chance an AI copyright case reaches the Supreme Court.
Second: Compensation Models
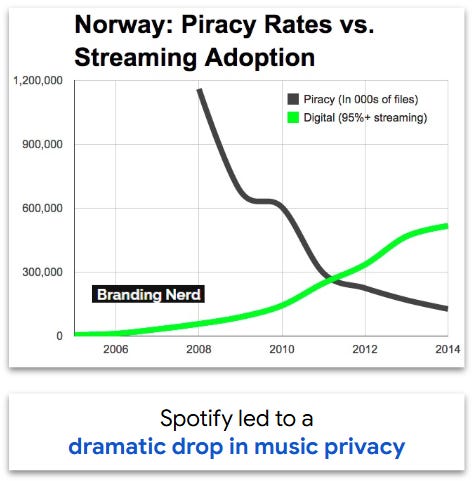
What AI solutions emerge that benefit users and creators? The early internet provides a valuable lesson: despite early legal victories that forced Napster to shut down, piracy remained rampant until Spotify launched. In addition to being legal, Spotify was better for users, providing instant on-demand access to a virtually unlimited catalog of music.
New AI solutions are emerging; Adobe, Shutterstock and Getty images are extending their creator programs to include compensation for AI training. Meanwhile, Cloudflare (a global networking company that handles 20% of all Internet traffic) is building a tool for content owners to block unauthorized web crawlers.
Regulation could also help; California is proposing a new law that would require AI companies to disclose the sources used in model training. If enacted, this would serve as a key reference for compensating providers.
Third: AI’s Creative Frontiers
What new AI-based mediums come to life? The Internet birthed new formats like user-generated video, blogs and podcasts and made stars like Mr. Beast, Joe Rogan and Marques Brownlee household names. YouTube alone paid out $70 Billion to creators like these over the past 3 years.
AI will birth new formats and make existing ones more personalized and immersive. Artists are experimenting with AI-customized movies, books and videogames, AI-infused toys and “digital twin” avatars. These innovations are already testing the limits of copyright law: who owns an AI-generated scene embedded in a movie? Who owns a “digital twin’s” AI-generated performance?
My Take: The Path Forward
500 years after Sabellico’s Venetian Privilege, the Internet revolutionized artistic content and AI is poised to do the same. While courts must ensure copyright evolves to protect creators and unleash AI’s creative potential, the winners of the future won’t be determined in courtrooms. Instead, it will be the artists and companies who build AI’s next Mr. Beast and Spotify that shape our creative future.

*Some lawsuits are based on examples of earlier models like GPT-3.5 regurgitating training content; newer models have mostly eliminated this behavior through fine-tuning.
Dad Joke: Why don’t Elton John’s songs have a copyright? So he can tell everybody “this is your song.” 😆